What a difference a compiler makes (adventures in SIMD world)
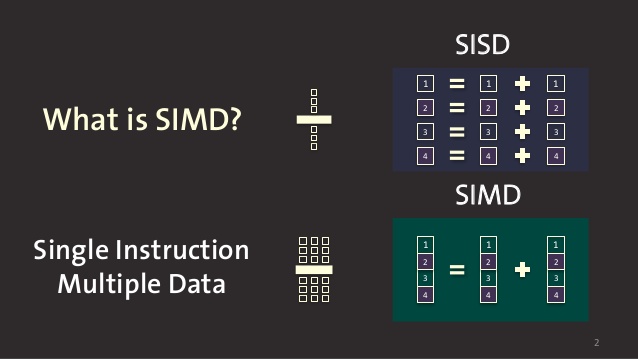
Single Instruction Multiple Data (SIMD) is a pattern found in modern microprocessors and which purpose is to accelerate the processing of data. A CPU is a data processing machine. It will transform data using instructions to produce a useful result like rendering an image in a game or training a neural network. As in everything in life, speed is of the essence, then executing those instructions as fast as possible is the holy grail of CPU designers. But they are alternative to designing ever faster CPU: designing CPU that can process data in parallel. Instead of having to repeat an instruction multiple time on a the multiple data, you execute that instruction once on multiple data.
Let's say you write a rendering engine which uses a log of linear algebra operations and you want to add two vectors. You could write something like this:
w[0] = u[0] + v[0]
w[1] = u[1] + v[1]
w[2] = u[2] + v[2]
which is going to take 3 instructions to finish (counting only add here). Or you could use some sort of SIMD instruction which would work like this:
w = u + v
it would perform the 3 additions using only one instruction, reducing the number of CPU cycles needed. Of course your CPU has to be designed for this, it can't be a software trick. You need special instructions that work on vectors (or arrays) of data and not on simple scalar values.
Credits: Alex Stojanov.
These instructions have been around for a while on x86 CPU, like the MMX instructions introduced in 1996. These instructions leverage registers of 64 bits which could contain simple 64 bits scalars or multiple "packed" value of 32, 16 or 8 bits. So let's say you want to add 16 values of 8 bits each. You could pack 8 of them in a 64 bits register, the other 8 in another register and perform an addition in one clock cycle thanks to these MMX instruction. A 8 X improvement !
After MMX came SSE, SSE2, SSE3, AVX and AVX2. These instruction sets would deliver more instructions beyond simple arithmetic computations and would work on bigger and bigger registers. Now is being deployed AVX512 though we are getting to the limit of what can be done on a consumer CPU. Indeed, the bigger the registers, the more complex the CPU become and those wide instructions can sometimes be counterproductive in some circumstances.
What a difference a compiler makes (adventures in SIMD world)
The purpose of this article is not to dig deep into SIMD programming, as I would be quite incapable of writing such article. Instead, it is to show you how two compilers, GCC of the Glorious GNU tool set and Clang, the challenger, treat those instruction sets.
Because indeed, those compilers learned, a long time ago, how to use those instructions to speed up your programs. Let's take this simple program:
#include <stdint.h>
typedef int32_t v4si __attribute__ ((vector_size (16)));
int main() {
v4si a = { 1, 2, 3, 4 };
v4si b = { 1, 2, 3, 4 };
v4si c = a + b;
}
Typedef syntax is described here. We are essentially creating a vector type of 16 bytes (128 bits) of base type int32_t (typedef int32_t[4] v4si). It's a short hand to describe a packed data type containing multiple scalars of the same integral type. When adding two of those, the compiler will automatically start using SIMD instructions. To see what the compiler is doing, compile with:
cc -S -g -fverbose-asm test.c
Options are the same for gcc and clang. This will produce a .s file (here called test.s). Here is the result for GCC/10.2.0 (some boiler plate and annotations removed for clarity):
main:
push rbp #
mov rbp, rsp #,
movdqa xmm0, XMMWORD PTR .LC0[rip] # tmp84,
movaps XMMWORD PTR [rbp-16], xmm0 # a, tmp84
movdqa xmm0, XMMWORD PTR .LC0[rip] # tmp85,
movaps XMMWORD PTR [rbp-32], xmm0 # b, tmp85
movdqa xmm0, XMMWORD PTR [rbp-16] # tmp87, a
paddd xmm0, XMMWORD PTR [rbp-32] # tmp86, b
movaps XMMWORD PTR [rbp-48], xmm0 # c, tmp86
mov eax, 0 # _4,
pop rbp #
ret
.LC0:
.long 1
.long 2
.long 3
.long 4
GCC and Clang produce more or less the same code and both use an MMX era instruction to perform move (movdqa) or addition (paddd). The later was introduced with MMX on 64 bits registers but here we use it on 128 bits packed data because it was extended on SSE2. By default, GCC and Clang will resort to SSE2 instructions which means that the binary generated will not be compatible with x86 CPU older than the Pentium 4 (circa 2000). You can always disable that behavior using -march.
What happens if we feed bigger vectors to our instructions? How does the compilers handle it? Let's try:
#include <stdint.h>
typedef int v4si __attribute__ ((vector_size (32)));
int main() {
v4si a = { 1, 2, 3, 4, 5, 6, 7, 8 };
v4si b = { 1, 2, 3, 4, 5, 6, 7, 8 };
v4si c = a + b;
}
# test.c:6: v4si a = { 1, 2, 3, 4, 5, 6, 7, 8 };
.loc 1 6 0
movl $1, -112(%rbp) #, a
movl $2, -108(%rbp) #, a
movl $3, -104(%rbp) #, a
movl $4, -100(%rbp) #, a
movl $5, -96(%rbp) #, a
movl $6, -92(%rbp) #, a
movl $7, -88(%rbp) #, a
movl $8, -84(%rbp) #, a
But GCC seems to cheat here. Because the result is pre-calculated and then stored in the executable data:
.LC0:
.long 2
.long 4
.long 6
.long 8
.align 16
.LC1:
.long 10
.long 12
.long 14
.long 16
And then loaded with SSE2 instructions:
# test.c:8: v4si c = a + b;
.loc 1 8 0
movdqa .LC0(%rip), %xmm0 #, tmp89
movaps %xmm0, -48(%rbp) # tmp89, c
movdqa .LC1(%rip), %xmm0 #, tmp90
movaps %xmm0, -32(%rbp) # tmp90, c
One has to assume that if GCC where not able to play tricks and actually performs the computation, it would probably behave badly. On the other hand, Clang does not cheat but seems smarter and will use two calls to a SSE2 instructions:
movaps .LCPI0_0(%rip), %xmm0 # xmm0 = [5,6,7,8]
movaps %xmm0, 80(%rsp)
movaps .LCPI0_1(%rip), %xmm1 # xmm1 = [1,2,3,4]
movaps %xmm1, 64(%rsp)
But what if we want to use newer instructions? With wider vectors? For example because we write specialized software running on controlled environment where we know the CPU will provide more recent instruction sets. Let's activate AVX instructions using the -mavx switch with gcc:
# test.c:6: v4si a = { 1, 2, 3, 4, 5, 6, 7, 8 };
.loc 1 6 0
vmovdqa .LC0(%rip), %ymm0 #, tmp89
vmovdqa %ymm0, -112(%rbp) # tmp89, a
# test.c:7: v4si b = { 1, 2, 3, 4, 5, 6, 7, 8 };
.loc 1 7 0
vmovdqa .LC0(%rip), %ymm0 #, tmp90
vmovdqa %ymm0, -80(%rbp) # tmp90, b
# test.c:8: v4si c = a + b;
.loc 1 8 0
vmovdqa .LC1(%rip), %xmm0 #, tmp91
vmovaps %xmm0, -48(%rbp) # tmp91, c
vmovdqa .LC2(%rip), %xmm0 #, tmp92
vmovaps %xmm0, -32(%rbp) # tmp92, c
movl $0, %eax #, _4
GCC will be using AVX instructions. Clang accepts the -mavx switch and generates code using AVX instructions too but it looks quite different:
.loc 1 6 8 prologue_end # test.c:6:8
vmovaps .LCPI0_0(%rip), %ymm0 # ymm0 = [1,2,3,4,5,6,7,8]
vmovaps %ymm0, 64(%rsp)
.loc 1 7 8 # test.c:7:8
vmovaps %ymm0, 32(%rsp)
.loc 1 8 12 # test.c:8:12
vmovaps 64(%rsp), %ymm0
.loc 1 8 16 is_stmt 0 # test.c:8:16
vmovaps 32(%rsp), %ymm1
.loc 1 8 14 # test.c:8:14
vextractf128 $1, %ymm1, %xmm2
vextractf128 $1, %ymm0, %xmm3
vpaddd %xmm2, %xmm3, %xmm2
vmovaps %xmm1, %xmm3
vmovaps %xmm0, %xmm4
vpaddd %xmm3, %xmm4, %xmm3
# implicit-def: %ymm0
vmovaps %xmm3, %xmm0
vinsertf128 $1, %xmm2, %ymm0, %ymm0
.loc 1 8 8 # test.c:8:8
vmovdqa %ymm0, (%rsp)
Way more instructions, but still AVX. But why is Clang produces more instructions? Again GCC is cheating. If you look below in the GCC output, into the data definitions, you will see GCC precomputes the result whereas Clang let the resulting code do the addition with vpaddd, an AVX instruction.
So as you can see, compilers can have different strategies to deal with extended instruction and SIMD behavior. As always, when dealing with performance, always test. Testing is what will give you the definitive answer to who is the fastest.
Epilogue: AVX512
Let's expand the vector further to 512 bits:
typedef int v4si __attribute__ ((vector_size (64)));
GCC regresses to a string of movl instructions, as before whereas Clang is still smart enough to use two AVX instructions. Activating the -mavx512f leads to an interesting situation. Both compilers are using AVX512 instructions but differently. GCC yields:
# test.c:6: v4si a = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16 };
.loc 1 6 0
vmovdqa64 .LC0(%rip), %zmm0 #, tmp89
vmovdqa64 %zmm0, -240(%rbp) # tmp89, a
# test.c:7: v4si b = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16 };
.loc 1 7 0
vmovdqa64 .LC0(%rip), %zmm0 #, tmp90
vmovdqa64 %zmm0, -176(%rbp) # tmp90, b
# test.c:8: v4si c = a + b;
.loc 1 8 0
vmovdqa64 -240(%rbp), %zmm0 # a, tmp92
vpaddd -176(%rbp), %zmm0, %zmm0 # b, tmp92, tmp91
vmovdqa64 %zmm0, -112(%rbp) # tmp91, c
Whereas Clang yields:
.loc 1 6 8 prologue_end # test.c:6:8
vmovdqa32 .LCPI0_0(%rip), %zmm0 # zmm0 = [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16]
vmovdqa32 %zmm0, 128(%rsp)
.loc 1 7 8 # test.c:7:8
vmovdqa32 %zmm0, 64(%rsp)
.loc 1 8 12 # test.c:8:12
vmovdqa64 128(%rsp), %zmm0
.loc 1 8 14 is_stmt 0 # test.c:8:14
vpaddd 64(%rsp), %zmm0, %zmm0
.loc 1 8 8 # test.c:8:8
vmovdqa64 %zmm0, (%rsp)